ClassViewer 的介绍及实现
ClassViewer是我最近开发的一个用于展示 jvm class 字节码的小工具。它是一个单纯的静态网页,完全使用浏览器端的 Javascript 开发。之所以开发这款工具,是因为我在开发 ToyJVM 的时候,需要常常校验 class 文件某一部分的字节码, 所以如果一款工具能够很方便的显示 class 文件各个部分的信息和字节码,对于 ToyJVM 的开发将会是一个非常大的帮助。
在开始写代码之前调研了一些类似的产品,主要有 jdk 自带的 javap、国外的 Java-Class-Viewer 以及国人开发的 classpy,它们都是非常不错的 class 文件分析工具,但是也存在着一些算不上缺陷的小问题。所以最终还是决定自己写一个适合自己小工具,同时也加深下 class 结构的理解。
在调研了目前的产品后,我也更加清晰了自己的目标。首先它的受众应该是有兴趣研究 jvm 的程序员,而它应该有这些特性:
- 不依赖于特定操作系统平台
它应该具备基本的跨平台的能力,因为程序员的 Mac 和 Linux 使用率很高。 - 无需复杂的安装和编译,无需用户有特定的知识背景
我不太希望用户拿到我的代码后,还需要安装相应的环境、了解一堆无关知识。
最终实现出来的工具是这样的:
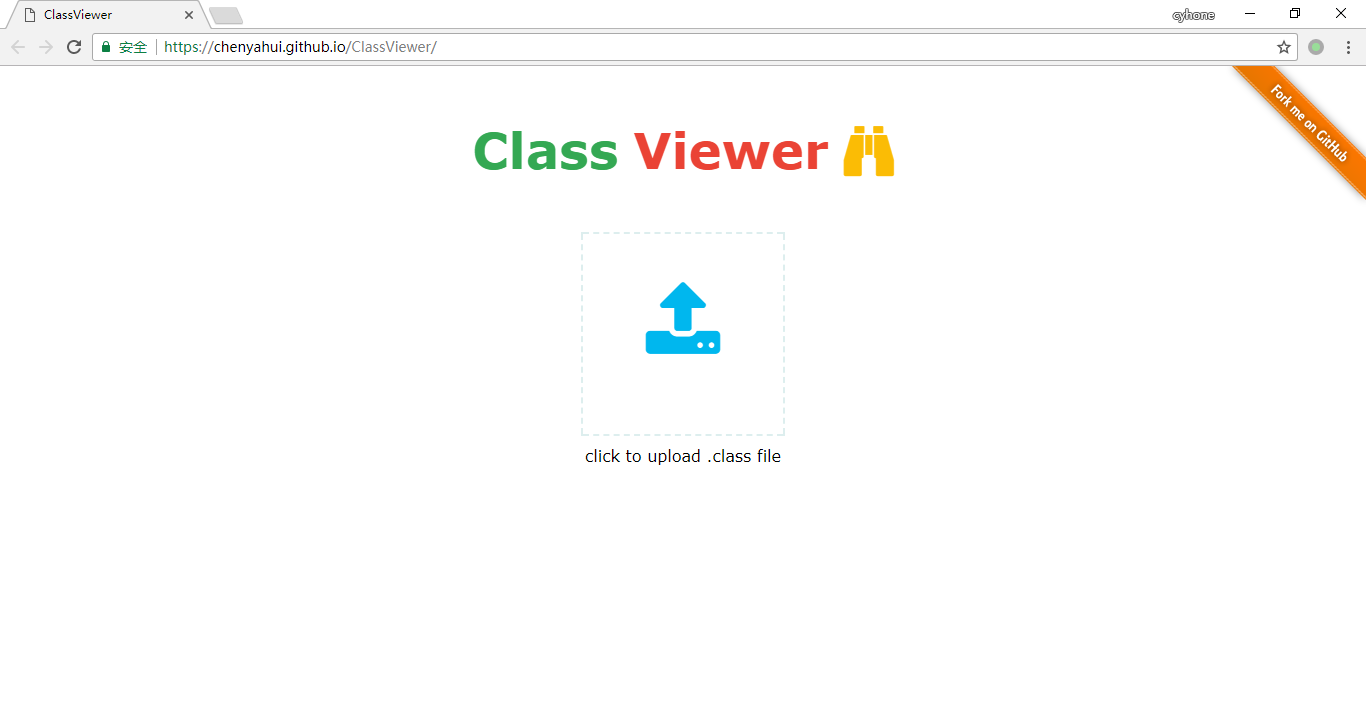
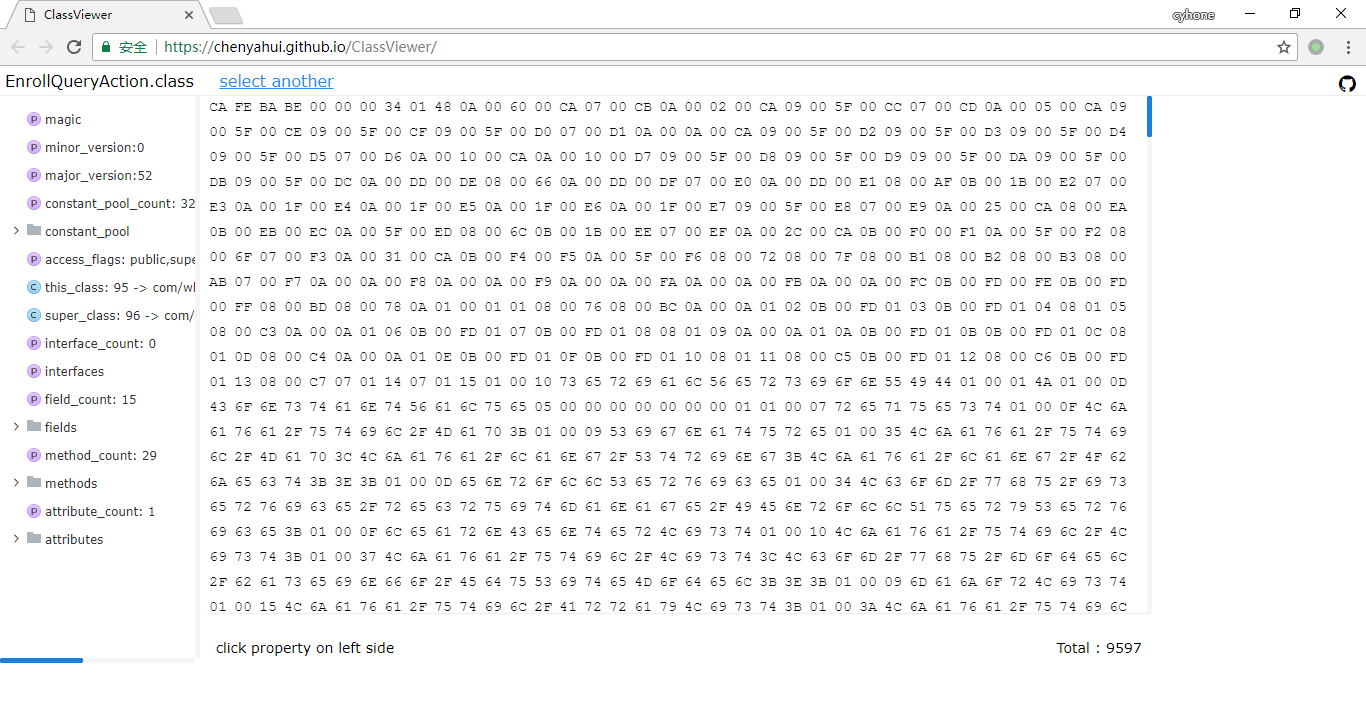
技术选型
基于浏览器来实现这个工具是非常符合我的需求的。首先网页跨平台能力是毋庸置疑的,只要有浏览器的电脑就可以运行这个工具。
其次,它不需要任何的编译和安装,也不需要用户有任何的背景知识才能使用。只要在 Github 下载好源码,在浏览器中打开 index.html 就可以运行使用。或者,直接访问 Github Page。所以我在开发这个工具的时候完全没有使用后台,也避免使用了各种前端工具链,尽可能的降低使用的复杂度。
我在开发中大量使用了 ES6 的特性,比如 let、模板字符串、类等和 ES7 中的 async。这是因为我实在是对 ES5 及其之前的 js 语法提不起太多兴趣,用起来实在是不爽。好在 ES6 提供了许多语法糖,解决了很多问题,用起来也算顺手。
也正因为我使用了一些 ES6 的特性,导致这个工具在低版本的浏览器上无法 work。这个问题后期也没打算解决,因为我认为程序员的浏览器应该都会支持这些特性。
使用 JavaScript 开发还有个问题就是,js 里面没有 int、short 和无符号类型,所有数字都是统一使用 Number 类型表示了。而对 jvm 的分析需要严格地按读取每个字节来说,是个非常头疼的问题。
好在 ES6 提供了 ArrayBuffer 和 DataView,可以方便的实现这些功能。
Class 文件的解析
在官方的 JVM S8 标准 的第四章中,给出了 Class 文件的格式结构。我们可以根据 jvm 标准来严格读取字节。
1 | ClassFile { |
以上代码定义了从上到下依次每部分的字节大小。
如果仔细看下这个结构定义,发现大部分数据都以 u2、u4 定义。其中 u4、u2 分别代表该部分占据 4 个字节和 2 个字节。比如 class 文件的前 4 字节,代表了 magic 这部分。接下来的 2 个字节代表了 minor_version。对于这种类型的数据,我们只要简单读取对应数目的字节就可以了。
但是还有两部分特殊的定义: cp_info 和 attribute_info。它们都属于复合结构,可以理解为 struct。
其中 cp_info constant_pool[constant_pool_count-1] 代表常量池,共有 constant_pool_count-1 项,每一项都是一个 cp_info 结构的数据。cp_info 的结构定义如下
1 | cp_info{ |
cp_info 包含多种类型的数据,比如 CONSTANT_Class_info、CONSTANT_String_Info 等,在 jvms8 中定义了 14 种 cp_info。每个 cp_info 的第一个字节都以 1 个字节的 tag 开头,代表了这个 cp_info 的类型。接下来每种 cp_info 各自的数据都不一样,比如 CONSTANT_Class_info 和 CONSTANT_Integer_info 的定义如下:
1 | CONSTANT_Class_info { |
CONSTANT_Class_info 代表在 tag 后,有 2 个字节的 name_index,就读取结束了。而 CONSTANT_Integer_info 在 tag 后有 4 个字节才能读取结束。
对于这种常量池的解析来说,一种最直观的方法是可以这么做:
1 | for(int i = 1; i < constant_pool_count; i++){ |
由于我们后期要用到 cp_info 的每个字段,所以需要把每个 cp_info 的定义表示为一个类。使用工厂方法来根据 tag 生成相应的对象,将读取的部分包含在各自类的 read 方法中。代码如下:
1 | cp_info cpInfoFactory(u1 tag){ |
目前这样看起来似乎我们只需要为 cp_info 定义 14 种不同的类,然后在类中为每个不同的 cp_info 定义不同的读取方法即可。
我目前在 ToyJVM 中是这么做的,但是这么做有个问题就是太繁琐了。我们需要为每个类定义不同的属性,然后在 read 方法中为这些属性读取不同的字节,极易出现编写错误。一旦一个字节读取错误,就会导致后面的字节全部错误。
由于 ClassViewer 采用了 js 实现,可以使用 eval 动态定义变量。我采用了这么一种做法,来简化 constant_pool 的读取:
1 | class BaseCpInfo { |
首先在这里我定义了一个 BaseCpInfo, 作为所有 cp_info 的类。在子类中,只需要在 this.properties 定义相关字段的名称和字节长度就可以。在 read 的时候,使用父类公共的 read 方法,使用 eval 为每个子类读取字段内容。
这里需要注意的是,this.properties 我使用了数组来实现,而非字典。是因为这些属性是必须严格有序的,不可以颠倒顺序。而字典常常使用 Hash 来实现,并不保证顺序。
使用这种方法子类可以不用写 read 方法,减少了出错的可能。对于 constant_pool 来说,大概可以少写 14 个 read 方法。后面 attributes 也采用了同样的策略,也可以少写十几个方法。这对于开发效率的提升程度还是非常客观的。
这种写法代码写起来很爽,只是有个缺点就是 eval 的速度实在太慢,会极大降低运行效率。但是因为写起来实在是太爽了,只要从 jvm 标准中把每个类型的字节信息抄过来,定义一个公共的 read 方法就可以了。所以在后面我也没打算把它改写成非 eval 方式的读写,或许有可能写一个 codegen 脚本,但是都是后话了。
字节显示区域
在预览图中可以看到,中间有一块区域用于显示 Hex 字节码信息,这是一块超大的排列整齐的方格区域,用普通的 div+css 显然没法很好的实现。在我的实现中,使用了 canvas 绘制了字节码区域。具体代码可以参考 byte_painter.js
除了正常的绘制之外,还实现了部分区域高亮以及滚动到指定区域的功能。
左侧栏
左侧栏实际上就是直接调用了 ztree。在class_to_ztree.js 中,将读取到的 class 文件转换成了 ztree 的 node 节点。
为什么要特意提下左侧栏。哈哈,因为我是 jetbtrains 粉,特意从 jetbrians 官网上找了 IDE 中的 符号图标,替换了 ztree 的默认样式,算是对 jetbrains 的一个小小的致敬吧!
TODO
目前 ClassViewer 的初版已经发布,可以直接 通过 Github Page 查看页面 或者直接在 Github 上查看源码。接下来我会继续把开发重心放在 ToyJVM 上,但同时也会抽时间继续优化 ClassViewer 的使用体验。
接下的开发方向主要会集中在以下几点:
- Method 的字节码信息展示
当用户点击了 method 的时候,直接在中间区域显示对应的 jvm 命令。这部分需要对 jvm 的命令进行解析,相应的功能我在 ToyJVM 中做过一遍,所以这个会是首选的实现功能。 - Index 之间跳转
jvm 中很多部分都是直接给了一个 index。比如 this_class,就是给了一个 2 个字节的 index,这个 index 表示constant_pool某一项的索引,这一项必须是CONSTANT_Class_info类型的。诸如此类,所以打算做一个可以根据 index 跳转对应真实数据的功能。 - 支持 jar 包的解析
故名思意,可以直接解析 jar 包。jar 包可以理解成一个 zip 压缩包,里面是一堆的 class 文件。所以这里我可能要借助第三方的 js 的 zip 解析包来实现。 - jvm s9 的支持
目前的 ClassViewer 是根据 jvms8 来实现的,接下来会跟进 jvm s9 的标准。 - Java modified UTF8 的解析
JVM 对标准 UTF8 进行了一些轻微的修改,称为 M-UTF8。我目前的实现都是直接使用标准的 UTF8 来解析的,这么做可以适合大部分的场景,对于一些特定字符会有问题,接下来会对这部分进行处理。
有感兴趣的可以和我一起跟进这个项目。
总结
开发这个工具的最大目的还是自用,实现一个适合自己和大部分人的 Class 字节码工具,除此之外也是对 JVM class 的进一步的研究。这个项目如果继续深入下去,甚至可以使用 js 来实现一个玩具版的虚拟机。但是对我来说没必要了,我会把对 JVM 的实现都放在 ToyJVM 中。
我在开发过程中最初打算尽可能地不依赖任何三方库,以便界面和功能上更贴近自己的体验。但是个人的能力始终有限,把时间花在工具的核心内容之外,实在有些得不偿失。所以还是用了一些开源项目,比如使用 ztree 实现了左侧信息栏,iziModal 实现了遮罩层,也用了 fontawesome 的一些图标来美化界面。最后也非常感谢这些项目对 ClassViewer 的帮助。