Golang 标准库限流器 time/rate 实现剖析
限流器是微服务中必不缺少的一环,可以起到保护下游服务,防止服务过载等作用。上一篇文章 《Golang 限流器 time/rate 使用介绍》 简单介绍了 time/rate 的使用方法,本文则着重分析下其实现原理。建议在正式阅读本文之前,先阅读下上一篇文章。
上一篇文章讲到,time/rate 是基于 Token Bucket(令牌桶) 算法实现的限流。本文将会基于源码,深入剖析下 Golang 是如何实现 Token Bucket 的。其代码也非常简洁,去除注释后,也就 200 行左右的代码量。
同时,我也提供了 time/rate 注释版,辅助大家理解该组件的实现。
背景
简单来说,令牌桶就是想象有一个固定大小的桶,系统会以恒定速率向桶中放 Token,桶满则暂时不放。 而用户则从桶中取 Token,如果有剩余 Token 就可以一直取。如果没有剩余 Token,则需要等到系统中被放置了 Token 才行。
一般介绍 Token Bucket 的时候,都会有一张这样的原理图:
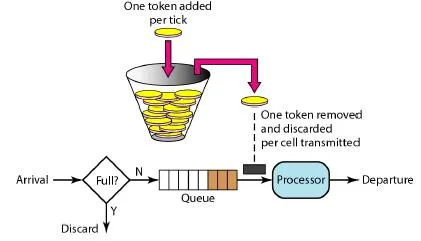
从这个图中看起来,似乎令牌桶实现应该是这样的:
有一个 Timer 和一个 BlockingQueue。Timer 固定的往 BlockingQueue 中放 token。用户则从 BlockingQueue 中取数据。
这固然是 Token Bucket 的一种实现方式,这么做也非常直观,但是效率太低了:我们需要不仅多维护一个 Timer 和 BlockingQueue,而且还耗费了一些不必要的内存。
在 Golang 的 timer/rate 中的实现, 并没有单独维护一个 Timer,而是采用了 lazyload 的方式,直到每次消费之前才根据时间差更新 Token 数目,而且也不是用 BlockingQueue 来存放 Token,而是仅仅通过计数的方式。
Token 的生成和消费
我们在 上一篇文章 中讲到,Token 的消费方式有三种。但其实在内部实现,最终三种消费方式都调用了 reserveN 函数来生成和消费 Token。
我们看下 reserveN 函数的具体实现,整个过程非常简单。在正式讲之前,我们先了解一个简单的概念:
在 time/rate 中,NewLimiter 的第一个参数是速率 limit,代表了一秒钟可以产生多少 Token。
那么简单换算一下,我们就可以知道一个 Token 的生成间隔是多少。
有了这个生成间隔,我们就可以轻易地得到两个数据:
1. 生成 N 个新的 Token 一共需要多久。time/rate 中对应的实现函数为 durationFromTokens。
2. 给定一段时长,这段时间一共可以生成多少个 Token。time/rate 中对应的实现函数为 tokensFromDuration。
那么,有了这些转换函数,整个过程就很清晰了,如下:
-
计算从上次取 Token 的时间到当前时刻,期间一共新产生了多少 Token: 我们只在取 Token 之前生成新的 Token,也就意味着每次取 Token 的间隔,实际上也是生成 Token 的间隔。我们可以利用
tokensFromDuration, 轻易的算出这段时间一共产生 Token 的数目。 那么,当前 Token 数目 = 新产生的 Token 数目 + 之前剩余的 Token 数目 - 要消费的 Token 数目。 -
如果消费后剩余 Token 数目大于零,说明此时 Token 桶内仍不为空,此时 Token 充足,无需调用侧等待。 如果 Token 数目小于零,则需等待一段时间。 那么这个时候,我们可以利用
durationFromTokens将当前负值的 Token 数转化为需要等待的时间。 -
将需要等待的时间等相关结果返回给调用方。
从上面可以看出,其实整个过程就是利用了 Token 数可以和时间相互转化 的原理。而如果 Token 数为负,则需要等待相应时间即可。
注意 如果当消费时,Token 桶中的 Token 数目已经为负值了,依然可以按照上述流程进行消费。随着负值越来越小,等待的时间将会越来越长。 从结果来看,这个行为跟用 Timer+BlockQueue 实现是一样的。
此外,整个过程为了保证线程安全,更新令牌桶相关数据时都用了 mutex 加锁。
我们模拟下请求与 Token 数变化的关系:
- 当某一时间,桶内 Token 数为 3, 此时 A 线程请求 5 个 Token。那么此时桶内 Token 不足,因此 A 线程需要等待 2 个 Token 的时间。 且此时桶内 Token 数变为 - 2。
- 同时,B 线程请求 4 个 Token,此时桶内 Token 数为 - 2,因此 B 线程需要等待 2+4=6 个 Token 的时间,且此时桶内 Token 数变为 - 6。
对于 Allow 函数实现时,只要判断需要等待的时间是否为 0 即可,如果大于 0 说明需要等待,则返回 False,反之返回 True。
对于 Wait 函数,直接 t := time.NewTimer(delay),等待对应的时间即可。
float 精度问题
从上面原理讲述可以看出,在 Token 和时间的相互转化函数 durationFromTokens 和 tokensFromDuration 中,涉及到 float64 的乘除运算。
一谈到 float 的乘除,我们就需要小心精度问题了。
而 Golang 在这里也踩了坑,以下是 tokensFromDuration 最初的实现版本
func (limit Limit) tokensFromDuration(d time.Duration) float64 {
return d.Seconds() * float64(limit)
}这个操作看起来一点问题都没:每秒生成的 Token 数乘于秒数。
然而,这里的问题在于,d.Seconds() 已经是小数了。两个小数相乘,会带来精度的损失。
所以就有了这个 issue:golang.org/issues/34861。
修改后新的版本如下:
func (limit Limit) tokensFromDuration(d time.Duration) float64 {
sec := float64(d/time.Second) * float64(limit)
nsec := float64(d%time.Second) * float64(limit)
return sec + nsec/1e9
}time.Duration 是 int64 的别名,代表纳秒。分别求出秒的整数部分和小数部分,进行相乘后再相加,这样可以得到最精确的精度。
数值溢出问题
我们讲 reserveN 函数的具体实现时,第一步就是计算从当前时间到上次取 Token 的时刻,期间一共新产生了多少 Token,同时也可得出当前的 Token 是多少。
我最开始的理解是,直接可以这么做:
// elapsed 表示过去的时间差
elapsed := now.Sub(lim.last)
// delta 表示这段时间一共新产生了多少 Token
delta = tokensFromDuration(now.Sub(lim.last))
tokens := lim.tokens + delta
if(token> lim.burst){
token = lim.burst
}其中,lim.tokens 是当前剩余的 Token,lim.last 是上次取 token 的时刻。lim.burst 是 Token 桶的大小。
使用 tokensFromDuration 计算出新生成了多少 Token,累加起来后,不能超过桶的容量即可。
这么做看起来也没什么问题,然而并不是这样。
在 time/rate 里面是这么做的,如下代码所示:
maxElapsed := lim.limit.durationFromTokens(float64(lim.burst) - lim.tokens)
elapsed := now.Sub(last)
if elapsed > maxElapsed {
elapsed = maxElapsed
}
delta := lim.limit.tokensFromDuration(elapsed)
tokens := lim.tokens + delta
if burst := float64(lim.burst); tokens > burst {
tokens = burst
}与我们最开始的代码不一样的是,它没有直接用 now.Sub(lim.last) 来转化为对应的 Token 数,而是
先用 lim.limit.durationFromTokens(float64(lim.burst) - lim.tokens),计算把桶填满的时间 maxElapsed。
取 elapsed 和 maxElapsed 的最小值。
这么做算出的结果肯定是正确的,但是这么做相比于我们的做法,好处在哪里?
对于我们的代码,当 last 非常小的时候(或者当其为初始值 0 的时候),此时 now.Sub(lim.last) 的值就会非常大,如果 lim.limit 即每秒生成的 Token 数目也非常大时,直接将二者进行乘法运算,结果有可能会溢出。
因此,time/rate 先计算了把桶填满的时间,将其作为时间差值的上限,这样就规避了溢出的问题。
Token 的归还
而对于 Reserve 函数,返回的结果中,我们可以通过 Reservation.Delay() 函数,得到需要等待时间。
同时调用方可以根据返回条件和现有情况,可以调用 Reservation.Cancel() 函数,取消此次消费。
当调用 Cancel() 函数时,消费的 Token 数将会尽可能归还给 Token 桶。
此外,我们在 上一篇文章 中讲到,Wait 函数可以通过 Context 进行取消或者超时等, 当通过 Context 进行取消或超时时,此时消费的 Token 数也会归还给 Token 桶。
然而,归还 Token 的时候,并不是简单的将 Token 数直接累加到现有 Token 桶的数目上,这里还有一些注意点:
restoreTokens := float64(r.tokens) - r.limit.tokensFromDuration(r.lim.lastEvent.Sub(r.timeToAct))
if restoreTokens <= 0 {
return
}以上代码就是计算需要归还多少的 Token。其中:
r.tokens指的是本次消费的 Token 数r.timeToAct指的是 Token 桶可以满足本次消费数目的时刻,也就是消费的时刻 + 等待的时长。r.lim.lastEvent指的是最近一次消费的 timeToAct 值
其中:r.limit.tokensFromDuration(r.lim.lastEvent.Sub(r.timeToAct)) 指的是,从该次消费到当前时间,一共又新消费了多少 Token 数目。
根据代码来看,要归还的 Token 要是该次消费的 Token 减去新消费的 Token。 不过这里我还没有想明白,为什么归还的时候,要减去新消费数目。
按照我的理解,直接归还全部 Token 数目,这样对于下一次消费是无感知影响的。这块的具体原因还需要进一步探索。
总结
Token Bucket 其实非常适合互联网突发式请求的场景,其请求 Token 时并不是严格的限制为固定的速率,而是中间有一个桶作为缓冲。 只要桶中还有 Token,请求就还可以一直进行。当突发量激增到一定程度,则才会按照预定速率进行消费。
此外在维基百科中,也提到了分层 Token Bucket(HTB) 作为传统 Token Bucket 的进一步优化,Linux 内核中也用它进行流量控制。