云风 coroutine 协程库源码分析
随着 Golang 的兴起,协程尤其是有栈协程 (stackful coroutine) 越来越受到程序员的关注。协程几乎成了程序员的一套必备技能。
云风实现了一套 C 语言的协程库,整体背景可以参考其 博客。
这个协程库非常轻量级,一共也才 200 多行代码,使用上更贴近于 lua 的写法(众所周知,云风是知名的 lua 粉)。整体基于 ucontext 和共享栈模型实现了有栈协程,代码质量毋庸置疑,本文将详细剖析该协程库的实现原理。
同时,我也提供了 coroutine 注释版,辅助大家理解 coroutine 的代码。
协程的背景
协程主要有两大优点:
- 相比线程更加轻量级
- 线程的创建和调度都是在内核态,而协程是在用户态完成的
- 线程的个数往往受限于 CPU 核数,线程过多,会造成大量的核间切换。而协程无需考虑这些
- 将异步流程同步化处理:此问题在知乎上有非常多的 经典回答。尤其在 RPC 中进行多服务并发协作的时候,相比于回调式的做法,协程的好处更加明显。这个对于后端程序员的意义更大,非常解放生产力。这里就不再赘述了。
微信基于 c++ 实现的协程库 libco,hook 了网络 IO 所需要大部分的系统函数,实现了当 IO 阻塞时协程的自动切换。关于libco的实现细节,可以阅读我的另外一篇文章: 《微信 libco 协程库源码分析》。
而 Golang 做的则更加极致,直接将协程和自动切换的概念集成进了语言。
协程再细分可以分为有栈协程和无栈协程。我们今天讲的云风的 coroutine,包括微信的 libco、Goroutine,都是属于有栈协程。无栈协程包括 ES6 中的 await/async、Python 中的协程等 以及 C++20 中的Coroutine。两种协程实现原理有很大的不同,本文主要基于云风的 coroutine 对有栈协程的原理进行详细的分析。
有栈协程的原理
一个程序要真正运行起来,需要两个因素:可执行代码段、数据。体现在 CPU 中,主要包含以下几个方面:
- EIP 寄存器:用来存储 CPU 要读取指令的地址
- ESP 寄存器:指向当前线程栈的栈顶位置
- 其他通用寄存器的内容:包括代表函数参数的 rdi、rsi 等等。
- 线程栈中的内存内容。
这些数据内容,我们一般将其称为 “上下文” 或者 “现场”。
有栈协程的原理,就是从线程的上下文下手,如果把线程的上下文完全改变。即:改变 EIP 寄存的内容,指向其他指令地址;改变线程栈的内存内容等等。
这样的话,当前线程运行的程序也就完全改变了,是一个全新的程序。
Linux 下提供了一套函数,叫做 ucontext 簇函数,可以用来获取和设置当前线程的上下文内容。这也是 coroutine 的核心方法。
coroutine 的使用
我们首先基于 coroutine 的例子来讲下 coroutine 的基本使用,以方便后面原理的讲解
1 | struct args { |
从代码看来,首先利用 coroutine_open 创建了协程调度器 S,用来统一管理全部的协程。
同时在 test 函数中,创建了两个协程 co1 和 co2,不断的反复 yield 和 resume 协程,直至两个协程执行完毕。
可以看出,最核心的几个对象和函数是:
struct schedule* S协程调度器coroutine_resume(S,co1);切入该协程coroutine_yield(S);切出该协程
接下来,会从这几点出发,分析 coroutine 的原理。建议大家在阅读下文时,同时对照我做的 coroutine 注释版。
struct schedule 协程调度器
1 | struct schedule { |
协程调度器 schedule 负责管理所有协程,有几个属性非常重要:
struct coroutine **co;是一个一维数组,存放了目前所有的协程。ucontext_t main;主协程的上下文,方便后面协程执行完后切回到主协程。char stack[STACK_SIZE];这个非常重要,是所有协程的运行时栈。具体共享栈的原理会在下文讲到。
此外,coroutine_open 负责创建并初始化一个协程调度器,coroutine_close 负责销毁协程调度器以及清理其管理的所有协程。
协程的创建: coroutine_new
1 | struct coroutine { |
coroutine_new 负责创建并初始化一个新协程对象,同时将该协程对象放到协程调度器里面。
这里的实现有两个非常有意思的点:
- 扩容:当目前尚存活的线程个数
nco已经等于协程调度器的容量cap了,这个时候需要对协程调度器进行扩容,这里直接就是非常经典简单的 2 倍扩容。 - 如果无需扩容,则需要找到一个空的位置,放置初始化好的协程。这里一般直接从数组第一位开始找,直到找到空的位置即可。但是云风把这里处理成从第
nco位开始寻找(nco代表当前存活的个数。因为一般来说,前面几位最开始都是存活的,从第nco位开始找,效率会更高。
这样,一个协程对象就被创建好,此时该协程的状态是 READY,但尚未正式执行。
coroutine_resume 函数会切入到指定协程中执行。当前正在执行的协程的上下文会被保存起来,同时上下文替换成新的协程,该协程的状态将被置为 RUNNING。
进入 coroutine_resume 函数的前置状态有两个 READY 和 SUSPEND,这两个状态下 coroutine_resume 的处理方法也是有很大不同。我们先看下协程在 READY 状态下进行 coroutine_resume 的流程。
coroutine_resume(READY -> RUNNING)
这块代码比较短,但是非常重要,所以我就直接贴代码了:
1 | // 初始化 ucontext_t 结构体,将当前的上下文放到 C->ctx 里面 |
这段函数非常的重要,有几个不可忽视的点:
getcontext(&C->ctx);初始化 ucontext_t 结构体,将当前的上下文放到 C->ctx 里面C->ctx.uc_stack.ss_sp = S->stack;设置当前协程的运行时栈,也是共享栈。C->ctx.uc_link = &S->main;如果协程执行完,则切换到S->main主协程中进行执行。如果不设置, 则默认为 NULL,那么协程执行完,整个程序就结束了。
接下来是 makecontext,这个函数用来设置对应 ucontext 的执行函数。如上,将 C->ctx 的执行函数体设置为了 mainfunc。
makecontext 后面的两个参数也非常有意思,这个可以看出来是把一个指针掰成了两个 int 作为参数传给 mainfunc 了。而在 mainfunc 的实现可以看出来,又会把这两个 int 拼成了一个 struct schedule*。
那么,为什么不直接传 struct schedule* 呢,而要这么做,通过先拆两半,再在函数中拼起来?
这是因为 makecontext 的函数指针的参数是 uint32_t 类型,在 64 位系统下,一个 uint32_t 没法承载一个指针, 所以基于兼容性的考虑,才采用了这种做法。
接下来调用了 swapcontext 函数,这个函数比较简单,但也非常核心。作用是将当前的上下文内容放入 S->main 中,并将 C->ctx 的上下文替换到当前上下文。这样的话,将会执行新的上下文对应的程序了。在 coroutine 中, 也就是开始执行 mainfunc 这个函数。(mainfunc 是对用户提供的协程函数的封装)。
协程的切出:coroutine_yield
调用 coroutine_yield 可以使当前正在运行的协程切换到主协程中运行。此时,该协程会进入 SUSPEND 状态
coroutine_yield 的具体实现依赖于两个行为:
- 调用
_save_stack将当前协程的栈保存起来。因为 coroutine 是基于共享栈的,所以协程的栈内容需要单独保存起来。 swapcontext将当前上下文保存到当前协程的 ucontext 里面,同时替换当前上下文为主协程的上下文。 这样的话,当前协程会被挂起,主协程会被继续执行。
这里也有个点极其关键, 就是如何保存当前协程的运行时栈, 也就是如何获取整个栈的内存空间。
这里我们需要了解下栈内存空间的布局,即栈的生长方向是从高地址往低地址。我们只要找到栈的栈顶和栈底的地址,就可以找到整个栈内存空间了。
在 coroutine 中,因为协程的运行时栈的内存空间是自己分配的。在 coroutine_resume 阶段设置了 C->ctx.uc_stack.ss_sp = S.S->stack。根据以上理论,栈的生长方向是高地址到低地址,因此栈底的就是内存地址最大的位置,即 S->stack + STACK_SIZE 就是栈底位置。
那么,如何找到栈顶的位置呢?coroutine 是基于以下方法做的:
1 | void _save_stack(C,S->stack + STACK_SIZE); |
这里特意用到了一个 dummy 变量,这个 dummy 的作用非常关键也非常巧妙,大家可以细细体会下。因为 dummy 变量是刚刚分配到栈上的,此时就位于 栈的最顶部位置。整个内存布局如下图所示:
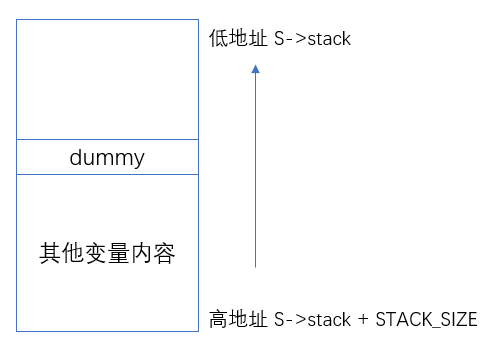
因此整个栈的大小就是从栈底到栈顶,S->stack + STACK_SIZE - &dummy。
最后又调用了 memcpy 将当前运行时栈的内容,拷贝到了 C->stack 中保存了起来。
coroutine_resume(SUSPEND -> RUNNING)
当协程被 yield 之后会进入 SUSPEND 阶段,对该协程调用 coroutine_resume 会再次切入该协程。
这里的实现有两个重要的点:
-
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size);
我们知道,在 yield 的时候,协程的栈内容保存到了 C->stack 数组中。
这个时候,就是用 memcpy 把协程的之前保存的栈内容,重新拷贝到运行时栈里面。这里有个点,拷贝的开始位置,需要简单计算下
S->stack + STACK_SIZE - C->size这个位置就是之前协程的栈顶位置。 -
swapcontext(&S->main, &C->ctx);交换上下文。这点在上文有具体描述。
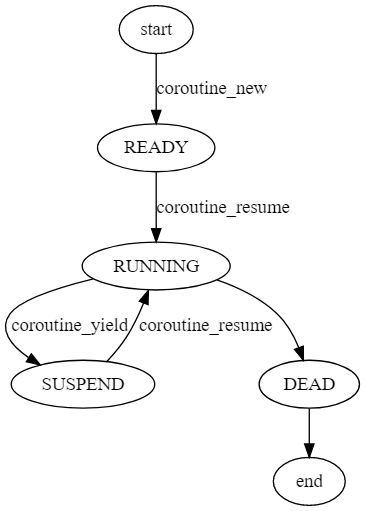
状态机转换
在 coroutine 中协程定义了四种状态,整个运行期间,也是根据这四种状态进行轮转。
共享栈
共享栈这个词在 libco 中提到的多,其实 coroutine 也是用的共享栈模型。
共享栈这个东西说起来很玄乎,实际原理不复杂,本质就是所有的协程在运行的时候都使用同一个栈空间。
有共享栈自然就有非共享栈,也就是每个协程的栈空间都是独立的,固定大小。好处是协程切换的时候,内存不用拷贝来拷贝去。坏处则是 内存空间浪费.
因为栈空间在运行时不能随时扩容,否则如果有指针操作执行了栈内存,扩容后将导致指针失效。为了防止栈内存不够,每个协程都要预先开一个足够的栈空间使用。当然很多协程在实际运行中也用不了这么大的空间,就必然造成内存的浪费和开辟大内存造成的性能损耗。
共享栈则是提前开了一个足够大的栈空间 (coroutine 默认是 1M)。所有的栈运行的时候,都使用这个栈空间。
conroutine 是这么设置每个协程的运行时栈:
1 | C->ctx.uc_stack.ss_sp = S->stack; |
对协程调用 yield 的时候,该协程栈内容暂时保存起来,保存的时候需要用到多少内存就开多少,这样就减少了内存的浪费。(即_save_stack 函数的内容)。
当 resume 该协程的时候,协程之前保存的栈内容,会被重新拷贝到运行时栈中。
这就是所谓的共享栈的原理。
总结
云风的协程库代码非常简约,可以帮助我们更好的理解协程实现的基本原理。但个人觉得这个协程库更像是个原型实现,很多地方在实际开发中并不足够好用。而微信的libco协程库利用系统hook,实现了协程的自动切换,更方便于工业级使用,用法也非常强大。具体可以参考我的另外一篇文章: 《微信 libco 协程库源码分析》。