微信 libco 协程库源码分析
libco 是微信后台开发和使用的协程库,同时也是极少数的直接将 C/C++ 协程运用到如此大规模的生产环境中的案例。
在 《云风 coroutine 协程库源码分析》 中,介绍了有栈协程的实现原理。相比云风的 coroutine,libco 在性能上号称可以调度千万级协程。 从使用上来说,libco 不仅提供了一套类 pthread 的协程通信机制,同时可以零改造地将三方库的阻塞 IO 调用进行协程化。
本文将从源码角度着重分析 libco 的高效之道。
在正式阅读本文之前,如果对有栈协程的实现原理不是特别了解,建议提前阅读 《云风 coroutine 协程库源码分析》。
同时,我也提供了 libco 注释版,用以辅助理解 libco 的源码
libco 和 coroutine 的基本差异
相比于云风的 coroutine 协程库, libco 整体更成熟,性能更高,使用上也更加方便。主要体现在以下几个方面:
- 协程上下文切换性能更好
- 协程在 IO 阻塞时可自动切换,包括 gethostname、mysqlclient 等。
- 协程可以嵌套创建,即一个协程内部可以再创建一个协程。
- 提供了超时管理,以及一套类 pthread 的接口,用于协程间通信。
关于 libco 的如何实现有栈协程的切换,co_resume、co_yield 是如何实现的。此部分内容已在 云风 coroutine 协程库源码分析 中进行了详细的剖析。各个协程库这里的实现大同小异,本文就不再重复讲述此部分内容了。
不过,libco 在协程的栈空间上有不一样的地方:
- 共享栈是可选的,如果想要使用共享栈模式,则需要用户自行创建栈空间,在 co_create 时传递给 libco。(参数
stCoRoutineAttr_t* attr) - 支持协程使用独立的栈空间,不使用共享栈模式。(默认每个协程有 128k 的栈空间)
- libco 默认是独立的栈空间,不使用共享栈。
除此之外,出于性能考虑,libco 不使用 ucontext 进行用户态上下文的切换,而是自行写了一套汇编来进行上下文切换。
另外,libco 利用 co_create 创建的协程, 需要自行调用 co_release 进行释放。这里和 coroutine 不太一样。
协程上下文切换性能更好
我们之前提到,云风的 coroutine 库使用 ucontext 来实现用户态的上下文切换,这也是实现协程的关键。
而 libco 基于性能优化的考虑,没有使用 ucontext,而是自行编写了一套汇编来处理上下文的切换, 具体代码在 coctx_swap.S。
libco 的上下文切换大体只保存和交换了两类东西:
- 寄存器:函数参数类寄存器、函数返回值、数据存储类寄存器等。
- 栈:rsp 栈顶指针
相比于 ucontext,缺少了浮点数上下文和 sigmask(信号屏蔽掩码)。具体可对比 glibc 的相关源码。
- 取消 sigmask 是因为 sigmask 会引发一次 syscall,在性能上会所损耗。
- 取消浮点数上下文,主要是在服务端编程几乎用不到浮点数计算。
此外,libco 的上下文切换只支持 x86,不支持其他架构的 cpu,这是因为在服务端也几乎都是 x86 架构的,不用太考虑 CPU 的通用性。
据 知乎网友的实验 证明:libco 的上下文切换效率大致是 ucontext 的 3.6 倍。
总结来说,libco 牺牲了通用性,把运营环境中用不到的寄存器拷贝去掉,对代码进行了极致优化,以换取很好的性能。
协程在 IO 阻塞时可自动切换
我们希望的是,当协程中遇到阻塞 IO 的调用时,协程可以自行 yield 出去,等到调用结束可以再 resume 回来,这些流程无需用户关心。
然而难点在于, 对于自己代码中的阻塞类调用尚且容易改造,可以把它改成非阻塞 IO,然后框架内部进行 yield 和 resume。但是大量三方库也存在着阻塞 IO 调用,如知名的 mysqlclient 就是阻塞 IO。对于此类的 IO 调用,我们无法直接改造,不便于和我们现有的协程框架进行配合。
然而,libco 的协程不仅可以做到 IO 阻塞协程的自动切换,甚至包括三方库的阻塞 IO 调用都可以零改造的自动切换。
这是因为,libco 巧妙运用了 Linux 的 hook 技术,同时配合了 epoll 事件循环,完美的完成了阻塞 IO 的协程化改造。
所谓系统函数 hook,简单来说,就是可以替换原有的系统函数,例如 read、write 等,将其替换为自己的逻辑。libco 目前所有关于 hook 系统函数的代码都在 co_hook_sys_call.cpp 中可以看到。
在分析具体代码之前,有个点需要先注意下:libco 的 hook 逻辑用于 client 行为的阻塞类 IO 调用。
client 行为指的是,本地主动 connect 一个远程的服务,使用的时候一般先往 socket 中 write 数据,然后再 read 回包这种形式。
read 函数的 hook 流程
我们以 read 函数为例,看下都做了什么:
ssize_t read(int fd, void *buf, size_t nbyte)
{
struct pollfd pf = {0};
pf.fd = fd;
pf.events = (POLLIN | POLLERR | POLLHUP);
int pollret = poll(&pf,1,timeout);
ssize_t readret = g_sys_read_func(fd,(char*)buf ,nbyte );
return readret;
}上述代码对原有代码进行了简略,只保留了最核心的 hook 逻辑。
注意:这里 poll 函数实际上也是被 hook 过的函数,在这个函数中,最终会交由 co_poll_inner 函数处理。
co_poll_inner 函数主要有三个作用:
- 将 poll 的相关事件转换为 epoll 相关事件,并注册到当前线程的 epoll 中。
- 注册超时事件,到当前的 epoll 中
- 调用 co_yield_ct, 让出该协程。
可以看到,调用 poll 函数之后,相关事件注册到了 EventLoop 中后,该协程就 yield 走了。
那么,什么时候,协程会再 resume 回来呢? 答案是:当 epoll 相关事件触发或者超时触发时,会再次 resume 该协程,处理接下来的流程。
协程 resume 之后,会接着处理 poll 之后的逻辑,也就是调用了 g_sys_read_func。这个函数就是真实的 linux 的 read 函数。
libco 使用 dlsym 函数获取了系统函数, 如下:
typedef ssize_t (*read_pfn_t)(int fildes, void *buf, size_t nbyte);
static read_pfn_t g_sys_read_func = (read_pfn_t)dlsym(RTLD_NEXT,"read");这个逻辑就非常巧妙了:
- 从内部来看,本质上是个异步流程,在 EventLoop 中注册相关事件,当事件触发时就执行接下来的处理函数。
- 从外部来看,调用方使用的时候函数行为和普通的阻塞函数基本一样,无需关系底层的注册事件、yield 等过程。
这个就是 libco 的巧妙之处了,通过 hook 系统函数的方式,几乎无感知的改造了阻塞 IO 调用。
此外,libco 也 hook 了系统的 socket 函数。在 libco 实现的 socket 函数中,会将 fd 变成非阻塞的 (O_NONBLOCK)。
那么,为什么 libco 连 mysql_client 都可以一并协程化改造呢?
这是因为 mysql_client 里面的具体网络 IO 实现,也是用的 Linux 的那些系统函数 connect、read、write 这些函数。 所以,libco 只用 hook 十几个 socket 相关的 api,就可以将用到的三方库中的 IO 调用也一起协程化改造了。
超时处理
默认情况下,阻塞IO不会超时。但可以通过设置setsockopt设置socket的SO_RCVTIMEO和SO_SNDTIMEO来调整超时时间。
但在libco里面,默认的读写超时时间为1s。例如对于read函数来说:
unsigned int timeout =
(lp->read_timeout.tv_sec * 1000) + (lp->read_timeout.tv_usec / 1000);
struct pollfd pf = {0};
pf.fd = fd;
pf.events = (POLLIN | POLLERR | POLLHUP);
poll(&pf, 1, timeout);
ssize_t ret = g_sys_read_func(fd, (char*)buf, nbyte);这里的lp->read_timeout在socket函数中被设置为默认的1s。
同时,libco也hook了setsockopt函数,当设置SO_RCVTIMEO或SO_SNDTIMEO,会调整read_timeout和write_timeout的超时时间,使其与阻塞IO的行为保持一致。
if (SO_RCVTIMEO == option_name) {
memcpy(&lp->read_timeout, val, sizeof(*val));
} else if (SO_SNDTIMEO == option_name) {
memcpy(&lp->write_timeout, val, sizeof(*val));
}以上是libco对于读写超时的操作。但是对于阻塞IO的connect来说,libco中将其设置为了75s。75s是内核默认的connect超时时间。如下:
int connect(int fd, const struct sockaddr* address, socklen_t address_len) {
...
for (int i = 0; i < 3; i++) // 25s * 3 = 75s
{
memset(&pf, 0, sizeof(pf));
pf.fd = fd;
pf.events = (POLLOUT | POLLERR | POLLHUP);
pollret = poll(&pf, 1, 25000);
if (1 == pollret) {
break;
}
}
...
}stCoEpoll_t 结构体分析
libco 的事件循环同时支持 epoll 和 kqueue,libco 会在每个线程维护一个 stCoEpoll_t 对象。
stCoEpoll_t 结构体中维护了事件循环需要的数据。
struct stCoEpoll_t
{
int iEpollFd;
co_epoll_res *result;
struct stTimeout_t *pTimeout;
struct stTimeoutItemLink_t *pstTimeoutList;
struct stTimeoutItemLink_t *pstActiveList;
};- iEpollFd:epoll 或者 kqueue 的 fd
- result: 当前已触发的事件,给 epoll 或 kevent 用。如果是 epoll 的话,则是 epoll_wait 的已触发事件
- pTimeout:时间轮定时管理器。记录了所有的定时事件
- pstTimeoutList:本轮超时的事件
- pstActiveList: 本轮触发的事件。
此外,libco 使用了时间轮来做超时管理,关于时间轮的原理分析网上比较多,这块也不是 libco 最核心的东西,就不在本文讨论了。
协程可以嵌套创建
libco 的协程可以嵌套创建,协程内部可以创建一个新的协程。这里其实没有什么黑科技,只不过云风 coroutine 中不能实现协程嵌套创建,所以在这里单独讲下。
libco 使用了一个栈来维护协程调用过程。
我们模拟下这个调用栈的运行过程, 如下图所示:
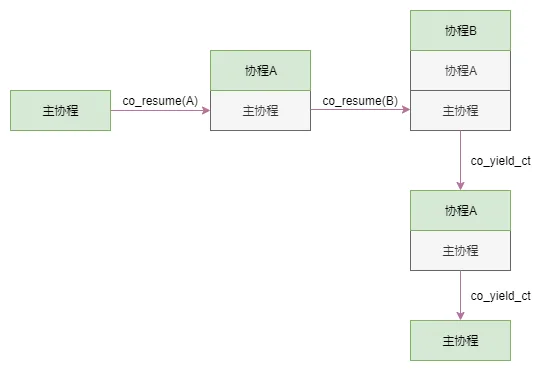
图中绿色方块代表栈顶,同时也是当前正在运行的协程。
- 当在主协程中 co_resume 到 A 协程时,当前运行的协程变更为 A,同时协程 A 入栈。
- A 协程中 co_resume 到 B 协程,当前运行的协程变更为 B,同时协程 B 入栈。
- 协程 B 中调用 co_yield_ct。协程 B 出栈,同时当前协程切换到协程 A。
- 协程 A 中调用 co_yield_ct。协程 B 出栈,同时当前协程切换到主协程。
libco 的协程调用栈维护 stCoRoutineEnv_t 结构体中,如下:
struct stCoRoutineEnv_t
{
stCoRoutine_t *pCallStack[128];
int iCallStackSize;
stCoEpoll_t *pEpoll;
};其中 pCallStack 即是协程的调用栈,从参数可以看出,libco 只能支持 128 层协程的嵌套调用,这个深度已经足够使用了。 iCallStackSize 代表当前的调用深度。
libco 的运营经验
libco 的负责人 leiffyli 在 purecpp 大会上分享了 libco 的一些运营经验,个人觉得里面的建议具体非常高的价值,这里直接引用过来。
协程栈大小有限,接入协程的服务谨慎使用栈空间;
libco 中默认每个协程的栈大小是 128k,虽然可以自定义每个协程栈的大小,但是其大小依然是有限资源。避免在栈上分配大内存对象 (如大数组等)。
池化使用,对系统中资源使用心中有数。随手创建与释放协程不是一个好的方式,有可能系统被过多的协程拖垮;
关于这点,libco 的示例 example_echosvr.cpp 就是一个池化使用的例子。
协程不适合运行 cpu 密集型任务。对于计算较重的服务,需要分离计算线程与网络线程,避免互相影响;
这是因为计算比较耗时的任务,会严重拖慢 EventLoop 的运行过程,导致事件响应和协程调度受到了严重影响。
过载保护。对于基于事件循环的协程调度框架,建议监控完成一次事件循环的时间,若此时间过长,会导致其它协程被延迟调度,需要与上层框架配合,减少新任务的调度;
总结
libco 巧妙的利用了 hook 技术,将协程的威力发挥的更加彻底,可以改良 C++ 的 RPC 框架异步化后的回调痛苦。整个库除了基本的协程函数,又加入类 pthread 的一些辅助功能,让协程的通信更加好用。
然而遗憾的是,libco 在开源方面做得并不是很好,后续 bug 维护和功能更新都不是很活跃。
但好消息是,据 leiffyli 的分享,目前有一些 libco 有一些实验中的特性,如事件回调、类 golang 的 channel 等,目前正在内部使用。相信后期也会同步到开源社区中。